1.今天把Spark编程第三个实验的Scala独立程序编程写完了。使用 sbt 打包 Scala 程序,然后提交到Spark运行。
2.完成了实验四的第一项

map(t => t.split(",")(0))表示:lines这个RDD中每个元素被split()函数拆分成3个字符串,保存到数组中,然后,把数组中的第1个元素(即学生名字字段的值)取出来放到新的RDD中。
distinct()表示:去重操作,即把重复的学生名字去掉,只保留一个。
count()表示:求去重后的学生总人数。

与第一问同理,只不过改为数组的第二个元素。

lines.filter(t => t.split(",")(0) == "Tom")表示:过滤掉数据集中第1个字段非“Tom”的名字,即只保留Tom的数据。
map(t => (t.split(",")(0), t.split(",")(2).toInt)) 表示:lines这个RDD中每个元素被split()函数拆分成3个字符串,保存到数组中,然后,把数组中的第1个元素和第3个元素取出来放到新的RDD中,.toInt的作用是把String类型的成绩值转变成Int类型,可以进行运算。
mapValues(x => (x,1))表示:构建(key, value)类型的键值对,其中,key表示Int类型的成绩,value表示数字"1"。
reduceByKey((x,y) => (x._1+y._1, x._2+y._2))表示:x._1+y._1表示把key(成绩)相加,x._2+y._2表示把value(数字“1”)相加。
mapValues(x => x._1/x._2)表示:总成绩/科目总数
values表示:返回value值(即平均成绩)。

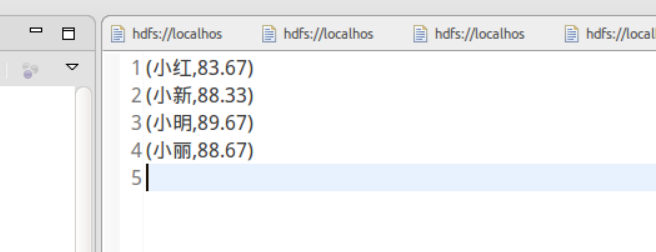
数据大概如下,仅展示部分结果如图: